Evolving technologies have developed into best practices to create secure, reliable, highly available, and adaptable data center spaces.

Learning objectives
- Explore the history, trends, and best practices that enhance data center design.
- Explain how to balance power usage effectiveness (PUE) and electrical efficiency with reliability when designing data center electrical distribution systems.
- Describe how to ensure that data center electrical systems are safe as well as reliable.
Designing increasingly efficient and reliable data centers continues to be a high priority for consulting engineers. From the continuity of business and government operations to the recent rise in new cloud services and outsourcing, the increasing demands on Internet service continually places strains on design, energy consumption, and the operators who make these facilities run. While designing to incorporate state-of-the-art systems and equipment, we must not forget the functional needs of the data center operators and facilities staff.
Design efficiency
Increasing Internet demands have strained server and storage capacity. In response, the number of servers needed continues to grow exponentially—even after the 2008 server virtualization revolution. To meet the infrastructure demands this has created, new data center power and cooling designs are providing expanded capacity and increased efficiency in every part of the design. Driven largely by the economics of energy lifecycle costs and the environmental realization of the vast amount of power that data centers require, inspirations to innovate have emerged across the electrical and information technology (IT) equipment space.
Efficiency has always been a requirement of integrated design. It could be summarized as an iterative process of balancing architecture and engineering responses to the natural environment the facility shares. The facility’s geographic location, orientation, and exposures to that environment play critical roles in the thermal exchanges that occur. This informs engineers regarding materials used for those exposures to efficiently balance mechanical and electrical designs. Efficient, nondestructive scaling is key. The infrastructure and systems within must be considered for capacity planning to serve the initial data center IT space efficiently. Care must be taken to create efficient operations at the initial low-demand levels and the ability to scale to future higher demands with minimal capital in oversizing and with no future disruptions.
Energy efficiency is important, but it does not complete the picture of design. Facilities also must provoke a human response. The perception of beauty, proportion, and style that inspires emotion is critical. Design is more than energy and performance. Integrated design—done well—produces an emotional response. We experience this when looking at a stylish car. The balance of form and function, combined with the place the facility shares in the environment, illustrate integrated design. Efficiency is only a part of the equation, but is the key to operational effectiveness and energy cost control over the life of the facility, just as engine performance and gas mileage are to a stylish ride. Here, the engineer can have a great impact on the economic and environmental concerns that support the business of data center operations.
The first data center energy efficiency metrics were summarized by the Green Grid. Founded in 2007 by the who’s who of data center IT equipment manufacturers, the Green Grid summarized power use effectiveness (PUE) in an equation that today remains a simple ratio showing how a data center uses mechanical and electrical infrastructure energy effectively.
PUE = total facility energy/IT equipment energy
The equation provides a simple way to compare the ideal data center PUE of 1.0 to the actual percentage associated with the electrical and mechanical systems needed. Total facility energy must contain all power needed to support the data center environment and the IT equipment within the data center. The resulting PUE, averaged over an annual basis, reflects the percentage above 1.0 required for non-IT equipment. For example, a PUE of 1.5 shows that in addition to the direct energy needed to operate servers, the network, storage, etc., the data center requires 50% more energy to support that equipment.
The arrival of PUE allows comparisons and competitions among data center designs located in similar climates and helps establish best practice design responses in similar climate zones. For example, a data center in the Iceland climate would compare poorly to an identical data center in South Florida. Mechanical cooling energy transfer into and out of the data center is strongly influenced by the environment the data center shares and the systems deployed.
Although PUE does not capture the IT hardware deployment efficiency (i.e., percentage virtualized, percentage used, etc.), it does normalize the result to reveal how well the electrical and largely the mechanical engineering response maintains the data center environment while lowering its impact on the natural environment.
PUE is only a measurement method. Many codes and standards have emerged over the last 10 years to specifically address data centers. ASHRAE has developed a comprehensive practical engineering response focused specifically on the uniqueness of data center environments. Efficient data centers and supporting space-engineering practices, tactics, and requirements are framed in ASHRAE’s TC9.9, Datacom Series Guidelines, and recent updates to ASHRAE 90.1: Energy Standard for Buildings Except Low-Rise Residential Buildings.
Electrical efficiency
Electrical system efficiency strives to minimize voltage and current conversion losses. The impedance in transformers, uninterruptible power supplies (UPSs), power supplies, lighting, mechanical equipment, and the wiring plant—combined with controls—affect electrical efficiency opportunities. Higher voltages to the rack, UPS bypass or interactive modes, and switch-mode power supplies form the heart of electrical energy advances. The use of transformers optimized to achieve efficient low-loss performance at lower loads (30% and above) have emerged as a mainstay. Increasingly, these transformers also deliver higher voltages (240 Vac) to the rack, which lowers IT equipment switch-mode power supply energy losses. Perhaps UPS systems have seen the most attention with improved conversion technologies and even line interactive operation mode. In the past, line interactive mode would have been considered risky.
With the equipment winding efficiency gains from transformers and motors, engineers must pay special attention to available fault current or available interrupting current (AIC) management. Higher efficiencies result in larger available fault current and, consequently, elevated arc flash hazards if not managed. NFPA 70E: Standard for Electrical Safety in the Workplace and contractor risk agents place safety above business continuity. Hence, minimizing AIC energy at the power distribution units is important to risk management within the data center space. Consideration should be given to current-limiting circuit breakers within the UPS distribution to lower fault energy and for selective coordination throughout the power chain. These efforts are a small undertaking for operational savings and enhanced safety.
To address the most common and often most physically destructive fault condition, ground faults, and simultaneously maintain the highest degree of availability, engineers must consider pushing ground fault interruption further into the distribution. By using ground fault detection and interruption to isolated individual main distribution segments, main breakers can be engaged at different fault conditions. Avoiding main breaker ground fault interruption should be a priority. Main switchgear provided with optic fault detection and current reduction circuitry—a relative newcomer to selective coordination—can isolate faults to switchgear compartments. Not to be disregarded, engineers may employ a high-resistance grounding design that allows ground faults to be sustained at lower energies until the location can be identified. Each approach comes with benefits and compromises that engineers must evaluate based on the electrical distribution strategy employed.
Electrical engineers also must pay close attention to the site’s soil conductivity when significant power conductors are located underground or under slabs. Energy losses from continuous high load factors require careful analysis to accurately size these underground feeders for the heating effects unique to the data center’s continuous loads. Following the analysis of load factors, concrete encasement, feeder oversizing, and spreading duct banks are to be expected to reduce the heating effects that data center load profiles create. In addition, soil reports allow accurate grounding calculations and identify the water table depth. Grounds that can reach the water table are very beneficial because of their low impedance.
New cloud-based data centers have pressed ever-higher power densities and load factors, which create a strong undertow for efficiency. To achieve 10 to 30 kW (or more) per rack load, designs may require the addition of cooling liquids to the rack, closely coupled redundant cooling, and thermal storage systems. Engineers must balance PUE and electrical efficiency with availability when designing data center electrical distribution systems that are in close proximity to water and other cooling liquids. The unique demands of creating an always-on and serviceable design that acknowledges failure potential—even those in response to water leaks at the rack level—are very critical. How operators will service an event without an outage remains a serious component in every design response.
Mechanical efficiency
Mechanical systems designed for data centers strive to manage machine efficiency, thermal transfer, controls, and air/water flow losses to achieve greater efficiency. Today’s best practice strategies must focus on airflow management and economizer operations. These include containment and variable airflow, air/water-side economization, and adiabatic humidification to achieve the greatest energy savings and lowest PUE. Controls remain critical in managing equipment and redundancies, but also should be employed to tune temperature and humidity conditions in the cold aisle.
Deep within data centers, there are unique thermal environments that architects and engineers must address together. Temperature and humidity conditions within many of the spaces require special attention to manage energy exchange with the surrounding spaces. Wall construction types, insulation levels, and vapor barriers are several factors that must be considered. Penetrations for air, water, electrical, and telecommunications infrastructure require special attention at these boundaries. Architects and engineers must manage the thermal-energy exchanges created by internal environments as they do modeling the facility’s exterior skin. Internal space temperature and humidity conditions should be accounted for by design. Containment solutions provide tight airflow management, but should be employed with proper consideration of the delta T across and through the containment structure and its adjacencies.
IT equipment manufacturers and data center operators play critical roles in energy management. This type of equipment consumes the most energy. Lowering IT energy consumption has the benefit of lowering electrical and mechanical system energy use and losses. Operators that focus on server virtualization, consolidation, and decommissioning combined with efficient power supply choices will greatly enhance data center performance. Together, this forms a complete picture of efficient data center IT operations.
Data centers will likely see 10 to 30 generations of varying IT equipment over the life of the facility. Informed by technology’s history and a vision of the future, we create efficient, adaptable environments that last long into the future. Energy efficiency will be one part of the conversation. Listening to the client is the next part.
Site-specific space considerations
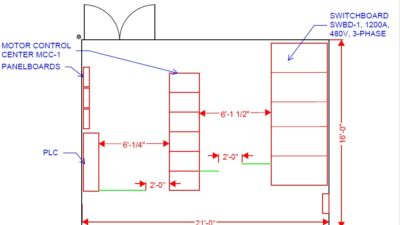
A data center’s proximity to ample electrical capacity, telecommunications carriers, and water utilities is a major priority. However, several other considerations play critical roles. Data center programming and planning must assess and address a variety of specific site and spatial needs (see Figure 1). Assessing the area within 5 miles of the site for potential threats, such as hazardous material operations, is critical. Accidents in these locations should have no effect on the mission critical operation.
Conceptual data center block plan
The data center site’s relationship to neighboring properties and roadways plays an important role in assessing and establishing appropriate levels of security. Planning physical structural setbacks for protection from manmade threats affects parking and access to entries and loading docks. Interior-space planning focuses on the logical spatial relationships and the sizes needed (see Figure 2). Requirements dictated by staffing and security posture affect where security and structural separations occur. Some spaces, such as mail processing, are increasingly outsourced or physically separated to control risk.
With the site established, accommodations can be made for exterior and interior electrical, mechanical, and energy storage systems. Within these spaces, an immense amount of power is required to keep the technology running as well as the cooling equipment that’s needed 24/7. Consequently, the management of energy and the creation of high availability are business necessities.
Business operations and continuity
Even with a redundant design in place, designers can continue to improve service continuity by striving to identify and mitigate the risks that cause downtime. A history of these causes shows ways that designers can help operations improve continuity and reduce costs. Studies (Ponemon Institute, 2010, 2013, 2016) show the cost of an outage ($5,000/minute in 2010 to $9,800/minute in 2016) grows as society’s reliance on data center information increases. Exponential growth and reliance necessitate continual action to manage the future’s higher expectations.
By providing data center facility managers with the tools and the information graphics necessary to operate and test their infrastructure, designers can help create even greater business continuity. More intuitive, responsive, and manageable systems improve knowledge and judgment when the operators must respond in a moment’s notice.
Mission critical reliability/availability, people, and intuition
The fundamentally important issues pushing design and operations of data center and mission critical facilities remain relatively unchanged. Highly available, efficient, and durable facilities that balance the client’s capital and operating cost requirements are the goal. These spaces are designed for tomorrow’s IT systems and for the people who will operate them. This is because of the increasing demand for the information these facilities generate and the data they store. Society now depends on data center services more than any other time in history, and that dependence continues to accelerate. Consequently, the need for the professionals that artfully combine IT equipment with those who can operate these facilities—without downtime—continue to increase (see Figure 3).
Reliable design in all infrastructure elements is key. Provide the simplest, most reliable series of delivery paths to serve the load redundantly. Paths should be isolated from each other and designed to allow the operators to service each element in that path without taking the data center down. Additional enhancements can be achieved by designing a path interconnection (such as electrically, with a static switch) at a point as close to the load as possible. Further physical separation of the delivery paths is also beneficial because it can prevent one causal event from taking both services down.
The calculation of reliability can be challenging. Many designers may question the completeness of the data used to calculate reliability. In addition, the calculation of reliability reveals little about the operator’s needs, only the equipment’s component parts. The operators’ time to respond and restore operations after an outage plays no part in reliability. Availability, however, captures the time to restore operations. The operator’s mean time to repair (MTTR) captures this critical time to evaluate, diagnose, assemble parts, repair, inspect, and return the system to service. This is a critical point. Mean time between failure (MTBF), the key factor in component reliability, does not speak to the critical challenges that operators face.
AI = MTBF/MTBF + MTTR
Where mean time between failure (MTBF) = uptime/number of system failures
MTTR = corrective maintenance downtime/number of system failures
Elsayed, E., Reliability Engineering, Addison Wesley, Reading, Mass., 1996
Looking at the available calculations, one should seem strikingly similar to PUE—a number that should be familiar to all designers. As with PUE, but inverted, by reducing the denominator (MTTR) to as near the zero repair time as possible, the best availability (of 1) can be achieved.
Regardless of whether designing telecommunications, power, cooling, water, security, or physical space, this framework of resilience is fundamental to the approaches underpinning the principles of managing and preventing disruptions. Even the best designs and operations can fail. What happens then to help the operator respond and restore service?
Operators often can be faced with designs that are quite complex and challenging to manage—even more so when facing stressful emergencies. Often adding to this complexity, the components are physically spread out throughout the facility, making it difficult for operators to physically monitor what is happening. Consequently, engineers should ensure that they are both designing data centers that increase the operator’s confidence in managing their systems and increasing availability by assisting in restoration following a planned or unplanned event.
Engineers must address the operator’s needs by creating carefully crafted methods of procedure that support the repeated testing of critical infrastructure components over the life of the facility. The passage of time should not weigh on the minds of the operators years after the initial commissioning of the data center. Designers can support the future need to disable, bypass, isolate, test, and respond to failure with less fear of customer disruption. Overly exaggerated mimic busses, text, and instructions that create intuitive understanding help operators face the extreme pressures of an outage. Listening to the operator’s concerns should become one of the primary post-occupancy objectives. With this driving principle, operators grow in confidence while managing their systems long into the future.
Creating the tool sets to operate the data center is important, but visibility and intuition are key. Data center infrastructure management (DCIM) software is an example of such a tool. DCIM tools have gained renewed popularity and offer many features that can help operators succeed. Operators need to see stranded capacity, plan the next IT deployment, and identify weaknesses in current operating capacity.
Additional tools are needed. The status and control of remote electrical and mechanical systems can be integrated so that—from one dashboard—the operator can get instant insight into the entire facility’s operational status. This concept can be scaled to a central control room with large simplified mimic buses, flow/status indicators, and remote operator handles that can simplify the task of understanding and operating the facility (see Figure 4). In a control room, operators can divert their attention from each item’s complexity and concentrate on the load status. This is not a new approach; power plants have done this for more than 50 years. Within a control room, designers can help operators comfortably observe their facility, build intuition, and work with a team to support each other when risk pressures rise.
Data center characteristics and the future
The characteristic of any data center can be derived from three factors:
- The IT mix and proportion used to deliver services
- The place and infrastructure that support that technology mix
- The vision of the people that support both.
Data center infrastructure design has always tried to intelligently predict and adapt to the future IT equipment that must be supported. Rapid, continual change is expected. The recent emergence of sufficient, low-cost bandwidth to homes and businesses has created greater opportunities to serve customers.
The rise of cloud computing and content-driven data centers have begun to separate from traditional enterprise IT services and equipment. Outsourcing data centers, such as Unisys, IBM, Infocrossing, and others, have been providing services for decades using standard equipment. However, cloud and content providers are creating custom IT equipment sets, such as servers with integral batteries, that are changing business structures. The effect these new equipment sets will have on the co-location, outsourcing, and enterprise data centers is unclear. However, the servers and storage trends they have created will be important to watch as future generations of IT equipment roll out.
Semiconductor manufacturers continue designing new generations of chips with increasing performance, lower cost, and smaller footprints. This size reduction and increased power consumption have been responsible for much of the design responses over the last several decades. It also has exposed design weaknesses in some facilities that must upgrade their infrastructure or face mounting unused white space. Over the last 20 years, unpredicted technologies have emerged that have prevented the mid-1990s predictions of more than 200 W/sq-ft data center loads by the early 2000s. Today, most data centers have yet to exceed 100 W/sq-ft. The future will also bring known and unknown technologies that will find their way to serve us. Technologies, such as quantum optical processors and direct-contact liquid cooling have the potential to breathe new life into the existing stock of more than 3 million U.S. data centers. One thing is certain: Data center characteristics are expected to continuously evolve.
The history and trends of data center design go back to 1960 and before. Management of evolving technologies has developed over time into best practices to create secure, reliable, and highly available spaces that must adapt to an ever-advancing future. History shows that humanity’s interdependence and increasing reliance on the information these facilities serve will not slow anytime soon. Over time, energy and connectedness remain central to design. Moreover, within all this hope and imagination, we must never forget the need to enhance inspiration and support the human element that operates these highly complex machines.
Scott Gatewood is an electrical engineer and senior associate at DLR Group. He leads mission critical and data center design for international co-location, financial services, transportation, and government companies.