When designing hyper scale data centers, consider elements of design, construction and commissioning.
Learning objectives
- Understand the market conditions affecting hyperscale and wholesale data centers.
- Gain tips on how to design data centers to support today’s hyperscale clients.
- Learn of the technical aspects of supporting hyperscale clients.
While some of the design elements differ from one hyperscale data center client to another, there are basic elements that are common with most hyperscale clients.
Per Techopedia, hyperscale computing refers to the facilities and provisioning required in distributed computing environments to efficiently scale from a few servers to thousands of servers. Hyperscale computing is usually used in environments such as big data and cloud computing. A co-location data center (sometimes called a co-lo facility) refers to a data center built and operated by a company that leases space to various end users of data within its facility. This allows the end users to avoid constructing their own data centers and locate their servers in locations across the world for connectivity.
For the past 10 years, co-location and wholesale data center providers have been focusing on enterprise clients. Enterprise clients are typically Fortune 1000 companies that use processing to support operations. Because the wholesale industry supports more than 85 percent of the enterprise market, wholesale data center owners are turning to support hyperscale. While the objectives are basically the same among hyperscalers and enterprise users, there are different philosophies and approaches.
Site selection
For more than 20 years, companies in data center site selection were driven by cost of power. While this is still true with hyperscale companies that look at cost per kWh, it also must be considered from a scalability factor, in some cases as high as 350 to 400 megawatt per site. This, combined with other factors, creates an issue with municipalities that also includes high water use.
Here are some of the business strategies that are behind site selection for hyperscale companies:
Reliability of power: Current and future capacity of the utility company is important to ensure a site can be powered, but another major theme among hyperscale clients is the reliability of electrical utility power, some which prefer a design of 99.999 percent. For that higher degree of reliability, hyperscalers prefer multiple diverse paths with underground service preferred to overhead service. In most cases, feeds are required from a minimum of two separate substations. It’s even better if they are different grids by different providers. In a few cases, dual power sources (nuclear and hydro) have been brought to the site to further enhance reliability.
Trends: In some cases when installing multiple feeds from different sources and at higher voltages, the engineering design may eliminate the need for standby generators for core processing. The network, however, is still backed up by standby generators.
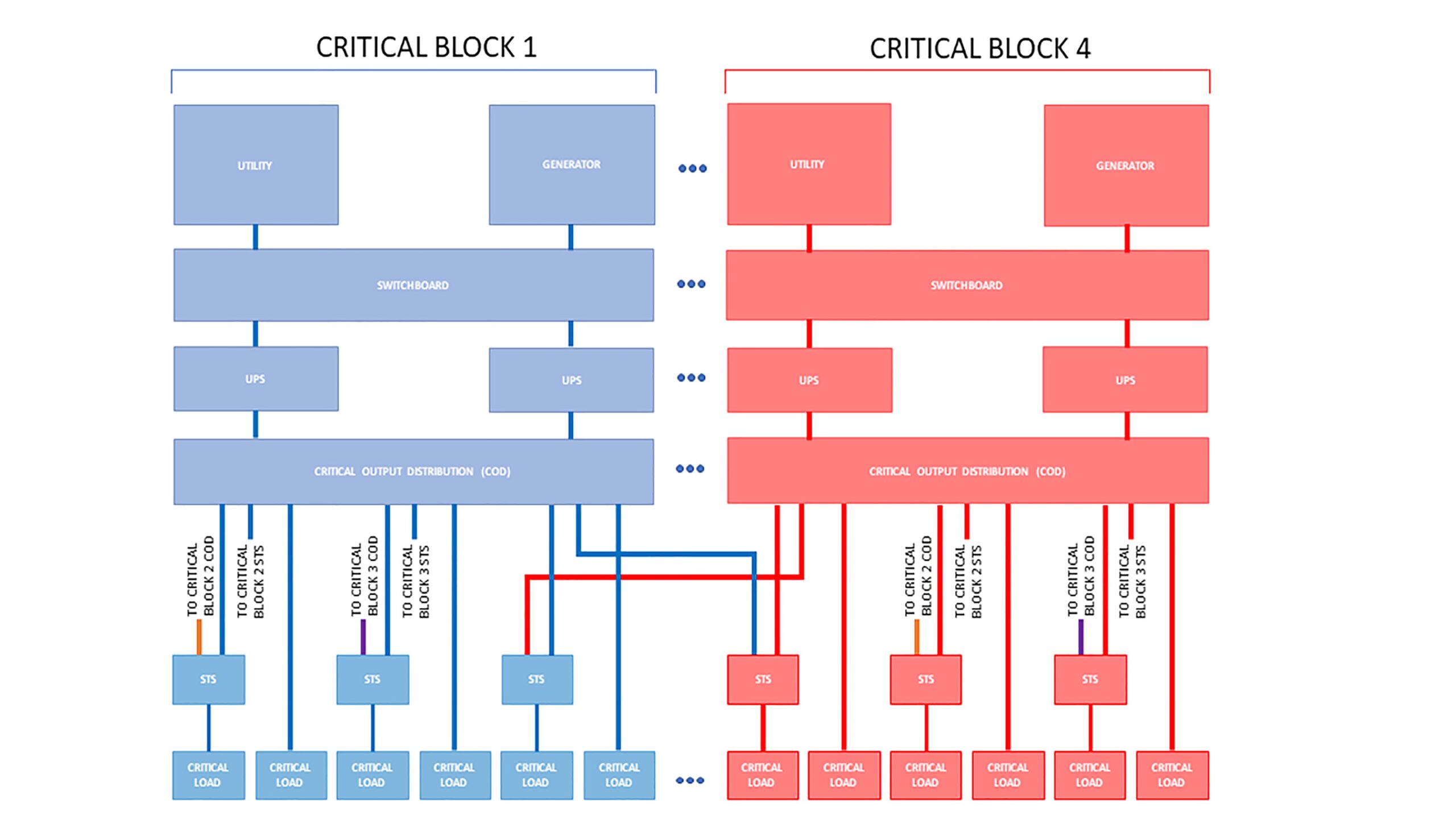
Additionally, the data center design internally affects how the utilities will comply to achieve 99.999 percent reliability. One electrical design concept is a catcher block configuration (see Figure 1), where a block is defined as a modular, repeatable distribution sub-system with both a utility and generator connection. In this configuration, primary critical blocks are the normal source for information technology (IT) power and cooling loads while a catcher (reserve) block mimics a primary block and becomes the backup power source in the case of a single failure on a primary block. The critical load is transferred almost instantaneously to the reserve block through static transfer switches so that no power interruption is encountered to critical loads during this transfer of power.
To maintain high level of reliability while minimizing costs, a maximum of six primary blocks are backed up by one catcher block are recommended. Therefore, to achieve the 99.999 percent reliability levels with a catcher block system, a redundant utility line is required to serve all primary blocks.
Another internal electrical design option is distributed redundant. This option eliminates static transfer switches (and inherently equipment failure points); instead the load is distributed to another distribution pathway with spare capacity. With this option, reliability studies show only one utility service to the site is sufficient to achieve 99.999 percent reliability.
Renewable energy: There is no doubt that these large data centers consume enormous amounts of power continuously. In a 2011 report, Greenpeace did a study on the carbon footprints of the top hyperscale data centers. As a result, some of the larger hyperscale companies have developed their own wind farms and solar energy plants to support their operation. Additionally, purchasing of energy credits further achieves their 100 percent renewable energy goals.
Water: As with energy, water conservation and usage has become a real issue among hyperscalers. Indirect evaporative or direct evaporative cooling seems to be the preferred design of hyperscalers.
Economic incentives: At the end of 2018, there were 26 states that offered tax incentives for building and operating data centers. While each state varies in the incentives, all offer a compelling case for reducing construction cost and operating cost. States that offer the large incentives seem to be getting most of the hyperscaler site selection business.
Design philosophies behind the hyperscale
While philosophies differ from hyperscaler to hyperscaler, there are some common design elements that are the same. One is that of reliance on server infrastructure and network reliability. Google for example, has been stripping its servers for years, reducing direct energy cost of operations. Additionally, batteries within the servers can now operate up to three hours of battery life, allowing for the redundancy to effectively be picked up within the network. In all cases though, the network is backed up by standby generators.
Within the last few years edge computing has become a trend within the industry. The fact is that edge has been a design philosophy among hyperscalers for years. Edge is a distributed multi-data center configuration to operate faster by locating data centers near central offices (CO) telecommunications providers. Edge also has important low latency applications such as gaming and trading. While some of the hyperscale companies build their core data centers in remote areas, they rely on smaller installations near highly populated areas, thus increasing general processing speeds. However, there are a few hyperscalers that operate their edge computing at the large core campuses.
Planning for capacity has always been an issue for hyperscale companies. As applications are developed, the growth of how that application will sell on the market creates unpredictable expansion projections. Here are some common design elements among hyperscalers that may differ from wholesale requirements of the past:
Design loads: Typically the average wholesale provider designs for 150-175 watts per square foot. In most cases this relates to approximately 7-8 kilowatt per rack. Hyperscalers will require 240-300 watts per square foot or 15 kilowatt per rack. Additionally, loads are taken as close to the equipment ratings as possible to reduce cost per megawatt. In the past, enterprise users were uncomfortable about this design philosophy of operating over 80 percent of capacity. Hyperscalers are willing to take it to the limit.
Additionally, the maximum capacity of a single building is based upon the size of the network, which equates to 24 to 32 megawatts of processing. While we are seeing dual minimum points of presence, the network design is typically a Tier II network, with four intermediate distribution frame closets running at 75 percent capacity in a distributed redundant configuration. While the network load is light, each expansion block of processing is typically built out in 2 to 4 megawatt increments.
Mechanical design: The preferred design varies from client to client, but the common theme of 1.125 annualized power usage effectiveness goal is constant. This is typically achieved by direct and or indirect evaporative cooling units. In addition, the hyperscale is comfortable at 90 degrees Fahrenheit intake at the server, whereas wholesale providers may need to stay within ASHRAE Technical Committee 9.9: Mission Critical Facilities, Data Centers, Technology Spaces and Electronic Equipment.
Building shell: In the past, wholesale data center providers have built nice interiors, and typically used precast or tilt-up construction. Hyperscalers do not care about interior finishes, and metal buildings are acceptable. The security, however, is increased for the hyperscale campuses versus what is typically found among wholesale data center providers.
Co-location for hyperscale design
The challenge among wholesale data center builders is to not create stranded capacity. This is difficult in a multi-tenant environment, especially if a hyperscale tenant is looking to lease space. Most pods, or self-contained units, are designed for a 1.5 megawatt (10,000 square feet at 150 watts per square foot) deployment. To install 3 megawatts per pod creates a risk of stranding capacity and thus is very expensive.
One philosophy is to create a design that supports both, hence the co-location for hyperscale design. If the mechanical cooling system is fed off its own dedicated distribution system, then a catcher block design concept in which the reserve block is sized larger than the standard primary blocks or is modular so that the addition of power modules to an uninterruptible power supply (UPS) increases the critical capacity of the reserve block can provide this flexibility.
For example, with the provisions of a 3 megawatt reserve bus, the wholesale provider has the capability to backup 300 watts per square foot in a single primary block for a hyperscale tenant. But if an enterprise client is looking for space, the primary block size can be reduced to adequately support that tenant without stranding capacity.
Another concept for the co-location for hyperscale design is creating smaller blocks where each block powers both critical IT and cooling loads. Therefore, a hyperscale tenant may require two of these smaller primary blocks while an enterprise tenant may require only one. In either case, the reserve block can maintain the same size as one of these primary blocks.
One of the important elements of design is balancing cost per megawatt and the speed-to-market approach. Lead times on equipment installation dramatically reduces the chance to win hyperscale tenants. The co-location for hyperscale design balances the procurement just-in-time process by using commodity components and skidding inventory. Typically, the equipment is sized for 1 megawatt UPS modules and 3 megawatt generators, all readily available components. In many cases, skid construction of the switchgear and UPS systems are pre-assembled to decrease schedule objectives. However, skidding does increase cost per megawatt, which may be offset by reducing general conditions in the schedule.
Commissioning hyperscale
In the past, design loads had a safety factor created to protect processing (typically 80 percent of the load) leaving a 20 percent buffer in load. That 20 percent buffer has an impact on cost per megawatt (about 10 percent overall), and hyperscale companies are willing to push the loads to the equipment rating. This philosophy does not affect operations but may have consequences during commissioning.
Therefore, hypserscalers are willing to adjust commissioning requirements to reduce cost. During the functional testing portion of commissioning, all equipment is individually tested to 100 percent of its rating. However, during integrated system test commissioning, the equipment won’t be tested at its full rating but instead at a lower level, such as at 90 percent of its capacity. The philosophy includes to build new when your loads hit 85 to 90 percent of rating.
Construction for hyperscale
While design/build is still used occasionally, design-bid-build is the preferred method of hyperscalers when considering the overall process. However, in many cases the contractor is competitively bid via a percentage of construction and brought in early to assist in the cost modeling. In most cases, the hyperscaler will have national contracts for equipment purchases, identifying a two-year anticipated purchase schedule. Many of the campuses under design have multiple buildings and are built in a phased construction. Project schedules for the large-scale data centers are at 12 months, with pod buildouts at three months.
UL Cloud Certification
Recently, UL created data center certification program UL 3223, which is based around hyperscale requirements. In the past, hyperscalers haven’t subscribed to programs such as the Uptime Institute Tier Classification System due to increased construction cost and obsolete requirements for today’s hyperscaler. For years UL has been the label of trust and integrity concerning safety and reliability.
Hyperscale customers (mobile device users) know of UL, and there is a statement of security to say the application’s infrastructure is UL Certified. Also, because the new standard is based upon hyperscale data centers, hyperscalers are using UL 3223 for a baseline comparison checklist when evaluating wholesale data centers. Both QTS and Iron Mountain have adapted UL 3223 for their data centers, as well as risk management from hyperscalers.
UL 3223 covers six areas of the design of the hyperscale data center. These include concurrently maintainable design, reliability, sustainability, commissioning, security and network design. The certification is conducted by teams of eight, encompassing all disciplines required within a design.
Additionally, UL is working with insurance underwriters to reduce premiums for property insurance that are UL Cloud Certified. With that said, the return on investment from investing in the certification should be approximately one to two years. The benefit for the industry is that if a wholesale data center provider is UL Cloud Certified, hyperscale tenants will know that the facility complies to hyperscale requirements. Currently, there is a lot of time investigating wholesale sites to see if they comply to hyperscale. UL Cloud Certification eliminates the time wasted by hyperscalers to evaluate different designs and built conditions.



